编译器-PL0语法分析
本文主要按照笔者逻辑思考的顺序进行语法分析部分的说明。如有不明白的部分请见谅。(完整代码在文章最后,时间紧张可直接跳到文章末尾 ❤️)
Parser 主要框架搭建
在拿到词法分析部分的一个又一个的 Token 时,庞大的语法分析让我无法下手,我不知道如何利用这些 Token,也不知道将 PL/0 语言用上下文无关文法描述出来有什么用,但这并不妨碍我们先将上下文无关文法写出来(看懂)😎
上下文无关文法
上下文无关文法描述的 PL/0 语言:
-
Program → Block .
-
Block → [ConstDecl][VarDecl][ProcDecl] Stmt
程序块的基本结构是:常量定义、变量定义、过程定义、语句
-
ConstDecl → const ConstDef {, ConstDef} ; 常量定义
-
ConstDef → ident = number
-
VarDecl → var ident {, ident} ; 变量定义
-
ProcDecl → procedure ident ; Block ; {procedure ident ; Block ;} 过程定义
-
Stmt → ident := Exp | call ident | begin Stmt {; Stmt} end | if Cond then Stmt | while Cond do Stmt | ε
赋值语句、调用语句、begin-end 块语句、判断语句、循环语句
-
Cond → odd Exp | Exp RelOp Exp 条件表达式
-
RelOp → = | <> | < | > | <= | >= 关系运算符
-
Exp → [+ | − ] Term {+ Term | − Term} 表达式
-
Term → Factor {* Factor | / Factor}
-
Factor → ident | number | ( Exp )
-
ident:字母开头的字母 / 数字串
-
number:无符号整数
从上面的文法中我们可以得到以下的信息:
- 🤔:PL/0 语言有着严格的先后顺序,必须将常量的声明、定义以及变量的声明放在最前面,然后是过程的声明和定义,最后才是语句。
- 😎:过程里可以嵌套过程的定义,过程里也可以调用(call)其他的过程。
- 😴:分号的位置很重要,常量和变量声明和定义的最后有;过程名后有;过程体结束后有;语句(stmt)只有在 begin 中的语句中有。
- 😋:程序最后是以 . 结束的。
“封装”思想
有了上述的理解,我们终于知道程序的大概流程了。因为这里我们不用预测分析表(无回溯),而是直接采用递归下降分析(有回溯),所以对于流程的了解挺重要的。下面将结合流程图展开分析(这里先不着急写代码,一切都理解了写代码其实很快。
程序的入口:
我们进入程序的“大门”,遇到了一个程序体,这里的程序体就像另一扇门 🚪,一扇进去之后,兜兜转转还是从原处返回的门,出了这扇门,我们会遇到一个 . ,最终走到程序的末尾。
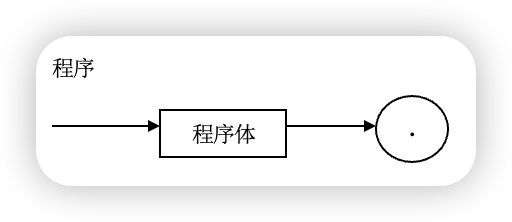
程序体:
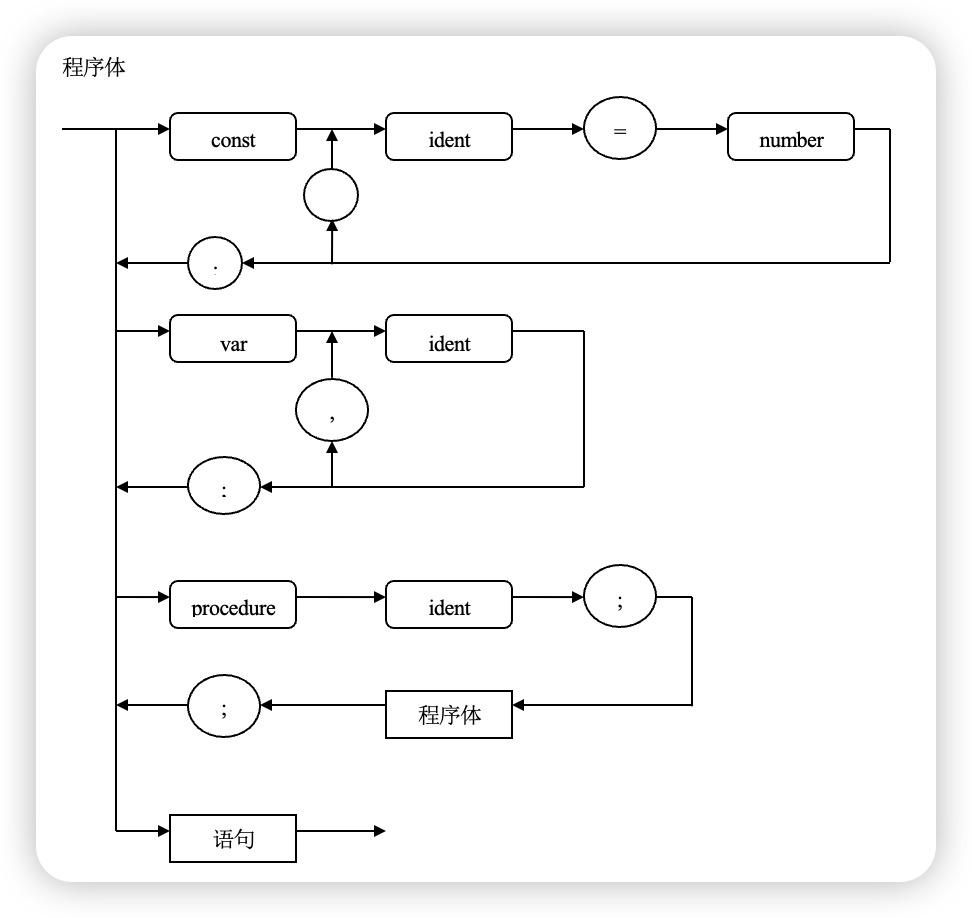
我们不妨走进这扇门,发现又有许多扇门 😵,但我们有一个竖向的“主线”,不妨就沿着主线走一遭。第一扇门上写了 const;第二扇门上是 var;第三扇和第四扇门分别是 procedure 以及“语句”,终于走到了“路”的尽头,因此我们的得到了程序体这个“房间”中有四扇不同的“门”。
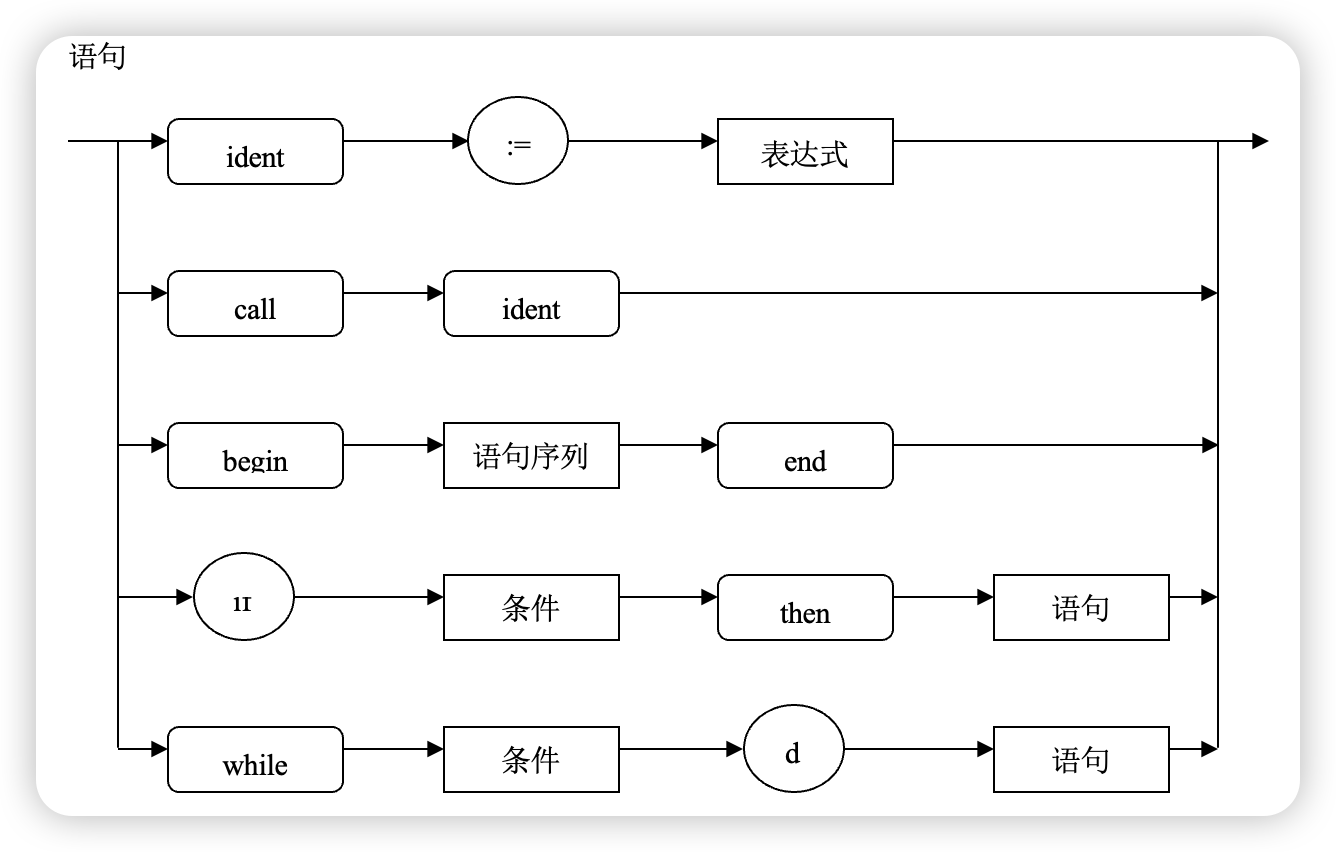
之后我们尝试打开“语句”的大门,这个房间内很容易看出来分了五路,一路上有一个门,但不同于上面的程序体,语句这五条路,你一次只能选一条!
show me the code
这样基本的“路线”,我们已经分析完了,但毕竟 talk is cheap. Show me the code 现在写完整的代码还为时尚早,不如用伪代码(可能是)代替。
我们从头开始,进入了一个程序之中,并在其中发现了程序体 🚪 和一个点号。门在这里我们用函数代替
prog(){
block();
match('.');
}
然后是程序体内部,有 const、var 和 procedure 和语句:
block(){
const();
var();
procedure();
statement();
}
最后是语句,有五个分支:
statement(){
// 对于以下五个只能选一个的条件限制会在后续补充
assign();
call();
begin();
if();
while();
// 空就不写了
}
下面就是根据上面的流程图,对于函数体内部的补充了。
prog(){
// 直接进入block,没有前兆
block();
match('.');
}
block(){
if match("const") const();
if match("var") var();
if match("procedure") procedure();
else statement();
}
statement(){
// 双引号内为终结符
if match(ident) assign();
if match("call") call();
if match("begin") begin();
if match("if") if();
if match("while") while();
// 空就不写了
}
程序体第一个分支–const。
const(){
do
match(ident);
match('=');
match(number);
while(match(',');)
match(';');
}
第二个分支–var
var(){
do
match(ident);
while(match(',');)
match(';');
}
第三个分支–procedure
procedure(){
match(ident);
match(';');
block();
match(';');
}
statement–assign
assign(){
match(ident);
match(':=');
expression();
}
statement–call
call(){
match(ident);
}
statement–begin
begin(){
do
statement();
while(!match("end");)
match("end");
}
statement–if
if(){
condition();
match("then");
statement();
}
statement–while
while(){
condition();
match("do");
statement();
}
还剩下之前我们声明但还没定义的函数:
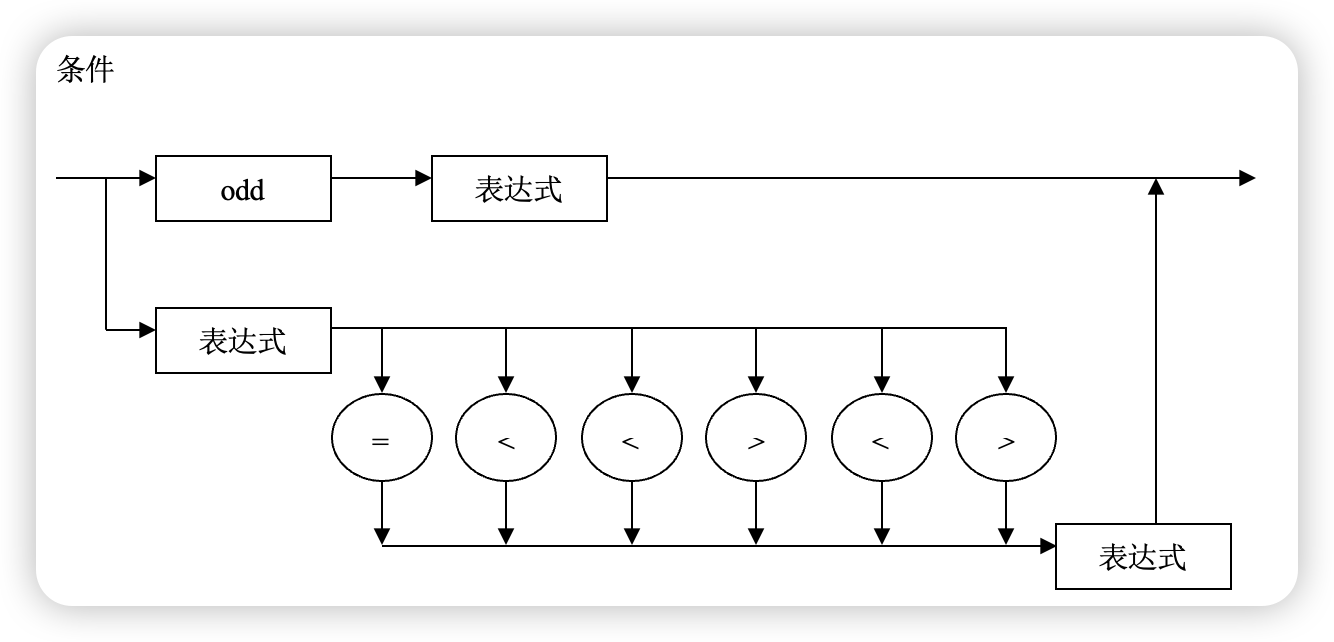
condition(){
if match("odd") expression();
else
expression();
if match(RelOp) expression();
}
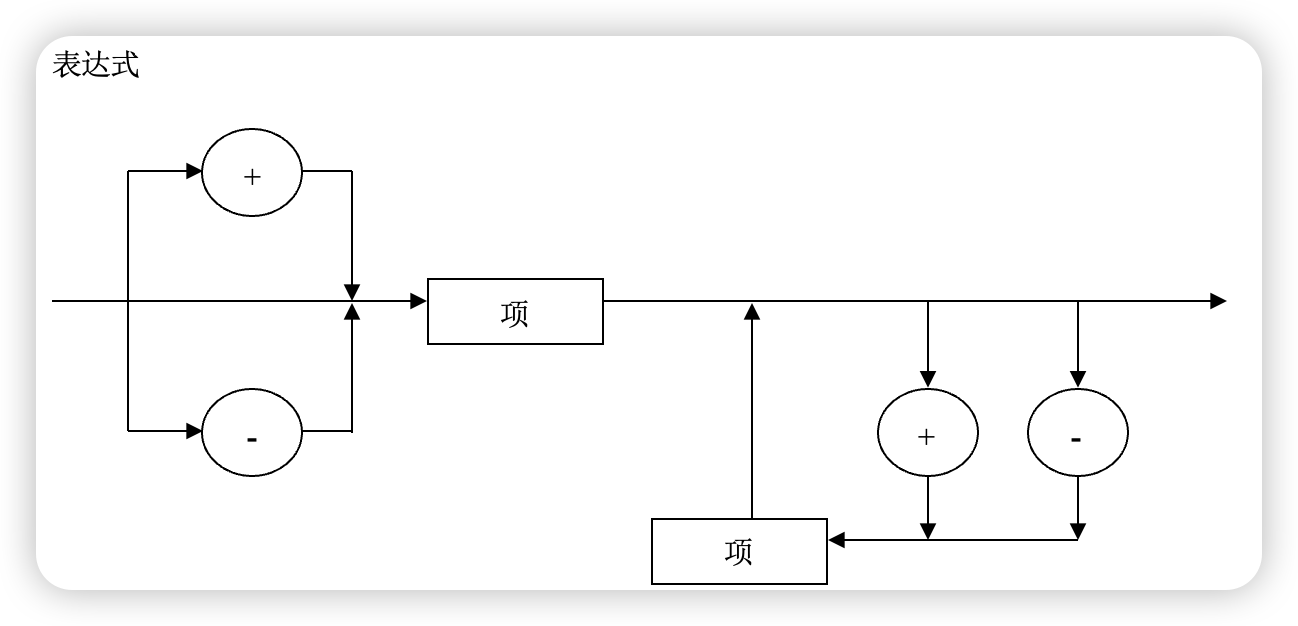
expression(){
if match('+' or '-') ...
do
term();
while(match('+' or '-');)
}
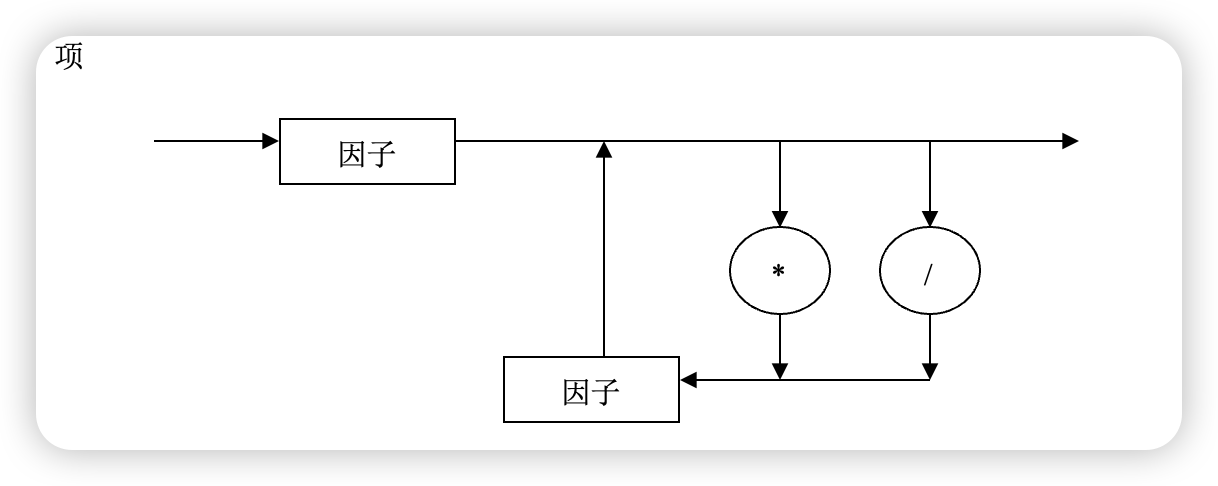
term(){
do
factor();
while(match('*' or '/');)
}
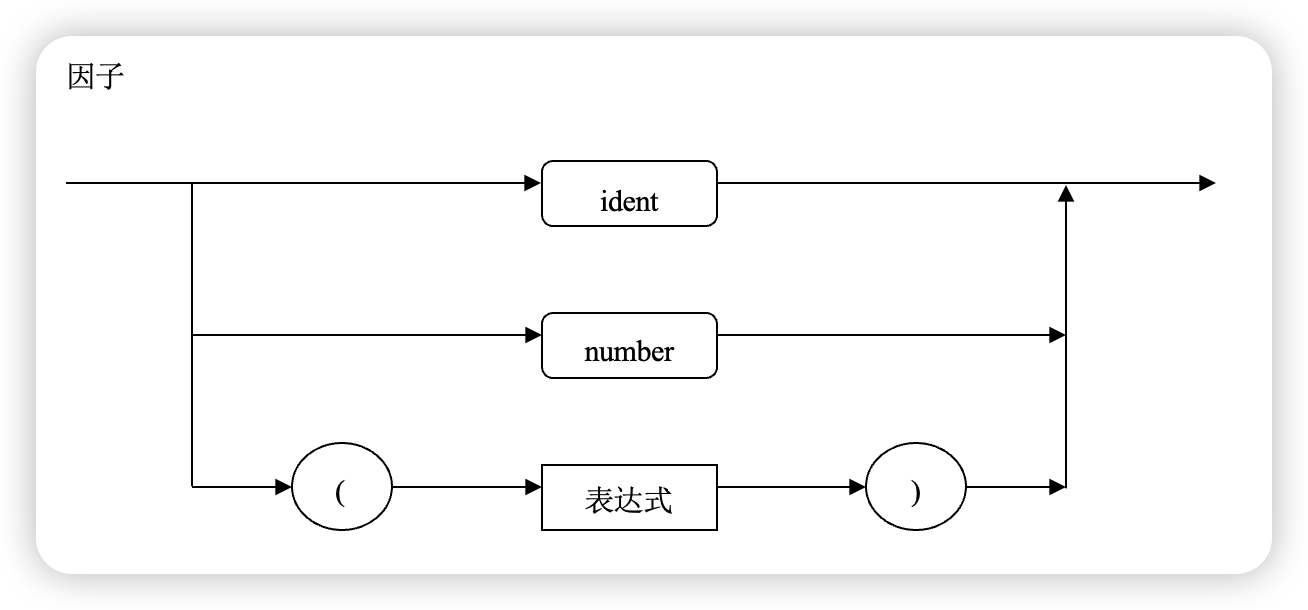
factor(){
if match(ident) ...
if match(number) ...
if match('(')
expression()
match(')')
}
下面我们将开始该次实验中两个最主要的部分–符号表的建立和中间代码的生成,之后会结合之前的代码,并在之前的基础之上进行扩写。
符号表的建立
从词法分析器(Lexer)中,我们能够得到一个又一个的连续的 Token,我们要对这些 Token 进行处理。在这个实验中,符号表就是保留部分有用 Token 信息的表格。
-
那符号表是什么呢?
符号表在这次实验中,存储的是常量、变量以及过程(Procedure)的信息。
那我们应该如何表示上述的信息呢?在这里我使用了 Java 中的 List 表示一整个表,List 里存放的是 Map,因为 Map 就是键值对,很好的满足我们的要求。正如下图所示,现在我们还不知道里面各字段的含义,但主要结构应该是这样的。
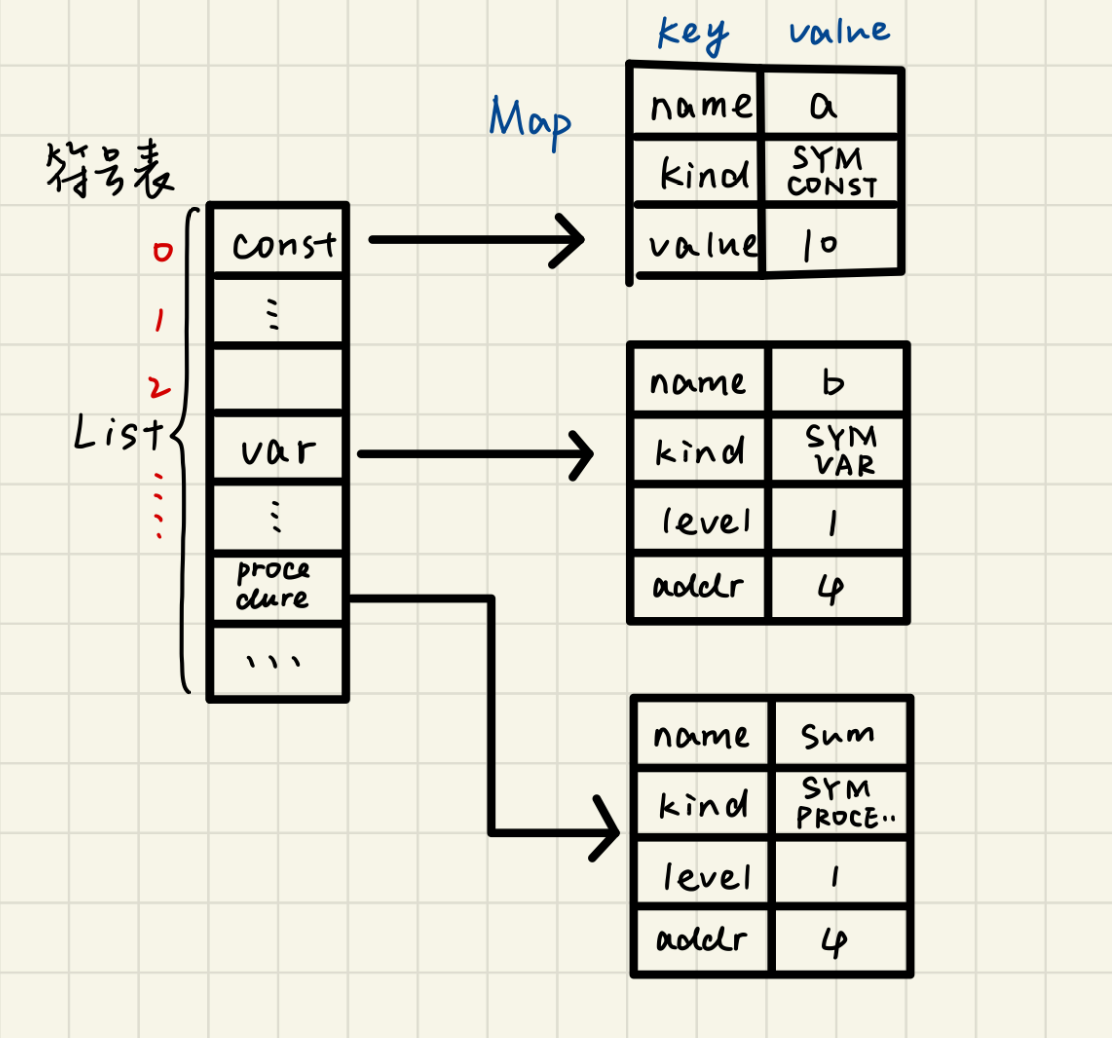
-
我们为什么要建立符号表呢?
其目的是方便之后的语义分析以及中间代码的生成,所以符号表其实是一个“工具”,有了它我们会变得更加方便,没有的话会遇到很多的麻烦,甚至无法分析。
举一个例子:之后我们会给变量赋值,如果变量在之前没有声明过,这是要报错的。如果我们不通过符号表记录下来,就无法知道这个变量声明还是没有声明,就无法处理了。
接下来,我们就要开始从零构建一个符号表了。
从之前的图中,我们看到符号表其实主要为三个部分: 常量、变量和过程(procedure)。
常量部分
常量有三个 Key,分别是:
- name:记录常量的符号名。
- kind:类型,即我们在词法分析中给他的“标签”
- value:常量的值。
这三个 Key 都是比较简单的,因为我们获取到一个 Token,Token 本身就包括 text(name)和 type(kind)属性,所以上面的三个 key 有两个直接给我们了,就还剩下一个 value,而通过分析 PL/0 语言的文法:
- ConstDecl → const ConstDef {, ConstDef} ; 常量定义
- ConstDef → ident = number
number 必然会跟在 ident 之后,所以第三个 value 的值,也是很简单就能够获取到,这样我们就完成了一个完整的常量 Map 的构造,接下来将其添加到 List 中就可以了。
因此我们先定义一个函数–enter,专门用来存入符号表。
const(){
do
match(ident);
match('=');
match(number);
enter(SYM_CONST);
while(match(',');)
match(';');
}
这里可能会疑惑,为什么传参只用传一个类型就够了呢?
- 这是因为 match 时,将 ident 和 number 已经存下了(全局),enter 可以直接获取。
变量部分
变量比常量稍微复杂一点,但总体流程不变。
变量共有四个 Key:
- name:记录变量的符号名。
- kind:类型,即我们在词法分析中给他的“标签”
- level:当前层次
- address:dx(当前全局变量的值)
var(){
do
match(ident);
enter(SYM_VAR);
while(match(',');)
match(';');
}
变量需要的 level 以及 address 也都是事先存好的,可以直接获取到,因此不需要传参。
过程部分
过程共有四个 Key:
- name:记录过程的符号名。
- kind:类型,即我们在词法分析中给他的“标签”
- level:当前层次
- address:程序地址
过程的添加是这三个中最麻烦的一个,原因就在于它的 address,虽然理解起来稍微有点难度,但实际添加不难。这牵扯到中间代码的生成,现在先卖个关子,不进行详细说明,只用知道 address 有点特殊就行了(详细解释部分在之后的 JMP 和 JPC 部分),其他的和前面两个的属性没有差别。
procedure(){
match(ident);
enter(SYM_PROCEDURE);
match(';');
block();
match(';');
}
中间代码的生成
我们这会来到最后一步–中间代码了,虽然之前的很多细节我们还不明白,但主要的框架已经搭起来了。在最后会有关于细节的“刻画”,或者🉑直接看源码,已经不会那么难懂了。
能够生成中间代码的产生式,实际上并不多,常量、变量和过程的声明实际上只是将它们加入到符号表中,并不会产生中间代码。
中间代码实际上就是以下这几条:
| 指令 / F | 含义 | L | A |
|---|---|---|---|
| LIT | 将常数置于栈顶 | — | 常量 |
| LOD | 将变量的值置于栈顶 | 层次差 | 数据地址 |
| STO | 将栈顶的值赋予某变量 | 层次差 | 数据地址 |
| CAL | 过程调用 | 层次差 | 程序地址 |
| INT | 在数据栈中分配空间 | — | 常量 |
| JPC,JMP | 条件 / 无条件转移 | — | 程序地址 |
| OPR | 一组算术或逻辑运算指令 | — | 运算类别 |
我们这一部分的目的就是将之前的源代码“翻译”为只通过上述八条指令表述的代码形式。
大概是长成这样:
0 F: JMP L: 0 A: 91
1 F: JMP L: 0 A: 2
2 F: INT L: 0 A: 5
3 F: LOD L: 1 A: 3
4 F: STO L: 0 A: 3
5 F: LOD L: 1 A: 4
6 F: STO L: 0 A: 4
7 F: LIT L: 0 A: 0
8 F: STO L: 1 A: 5
9 F: LOD L: 0 A: 4
...
这就有点抽象了 😩,实际上这也其实并不简单 😆。
上面是骗你的 🤪,其实不难。
主要是我们先了解上面那八条指令的具体含义和用法:
LIT
将常数置于栈顶,这条指令就是专门用于“运送”常数,是常数专用的。
为什么要送一个数到栈顶呢?因为我们是通过后缀表达式来运算的。
比如:两个常量做加法: 5+6。我们实际上是将其转换为了 56+。从左向右扫描(词法分析的工作),语法分析只是一个一个的获取 Token,首先获取到 5,发现是一个常数,送到栈顶(LIT),然后获取下一个 Token,是 6,再送到栈顶,最后获取到一个为+的 Token。将栈顶元素出栈得到 6,再将栈顶元素出栈得到 5,两者相加得到 11,送回栈顶。
指令为:
LIT 0 5
LIT 0 6
OPR 0 2 // 加法
这样就完成了一次加法运算,是不是很简单,但有时式子是 a+6,a 是一个标识符,这时我们需要查符号表,判断 a 是不是常量,是的话就获取它的值,放到栈顶。
之后我们进行思考 🤔,什么时候会使用常量的值,或者直接使用一个常数,其实只有一个地方,无数次递归之后,终究会到达 factor 这个函数。所以我们从这个函数体内部添加生成中间代码部分。(gen(F,L,A)函数是生成中间代码的函数,并会自动添加进中间函数表中,这个表和符号表差不多)
factor(){
if match(ident)
//查表
if const gen(LIT,0,val) // val是查表得到的值
if var ...
if procedure ...
if match(number) gen(LIT,0,number.val)
if match('(')
expression()
match(')')
}
LOD
将变量的值置于栈顶,这时的第一个参数也有了含义–层次差,这个参数的计算就是,当前的层次(调用该参数的位置)-符号表中存储的声明时的层次。为什么要这样呢?为了在第三次实验中使用,现在先不讨论。第二个参数是地址,每进入一个 block,dx 地址就会从 3 开始,因为前面还有三个固定的值,需要让出空间给它们,这些也是第三次实验要做的,所以先不说。
factor(){
if match(ident)
//查表
if const gen(LIT,0,val) // val是查表得到的值
if var gen(LOD,level-table.level,table.address)
if procedure ...
if match(number) gen(LIT,0,number.val)
if match('(')
expression()
match(')')
}
OPR
一组算术或逻辑运算指令,通过 LIT 和 LOD 指令我们已经将常量或者变量的值加入了栈里,接下来就是要让它们运算。这条指令的第一个参数没有意义,用 0 代替,第二个参数为运算符的类别。
操作码 m |
操作 | 描述 |
|---|---|---|
| 0 | RET |
返回,退出当前过程或函数,返回到调用过程。 |
| 1 | NEG |
取负,将栈顶元素的值取反。 |
| 2 | ADD |
加法,将栈顶的两个元素相加,结果存入栈顶。 |
| 3 | SUB |
减法,将次栈顶元素减去栈顶元素,结果存入栈顶。 |
| 4 | MUL |
乘法,将栈顶的两个元素相乘,结果存入栈顶。 |
| 5 | DIV |
除法,将次栈顶元素除以栈顶元素,结果存入栈顶。 |
| 6 | ODD |
判断栈顶元素是否为奇数,如果是,则将栈顶设为 1(真);否则,设为 0(假)。 |
| 7 | MOD |
取模,将次栈顶元素对栈顶元素取模,结果存入栈顶。 |
| 8 | EQL |
判断相等,次栈顶元素等于栈顶元素,则栈顶设为 1(真);否则,设为 0(假)。 |
| 9 | NEQ |
判断不等,次栈顶元素不等于栈顶元素,则栈顶设为 1(真);否则,设为 0(假)。 |
| 10 | LSS |
判断小于,次栈顶元素小于栈顶元素,则栈顶设为 1(真);否则,设为 0(假)。 |
| 11 | GEQ |
判断大于等于,次栈顶元素大于等于栈顶元素,则栈顶设为 1(真);否则,设为 0(假)。 |
| 12 | GTR |
判断大于,次栈顶元素大于栈顶元素,则栈顶设为 1(真);否则,设为 0(假)。 |
| 13 | LEQ |
判断小于等于,次栈顶元素小于等于栈顶元素,则栈顶设为 1(真);否则,设为 0(假)。 |
-
OPR 指令的作用
OPR指令的作用取决于操作码m的值,具体执行某种算术运算、逻辑判断或控制操作。对于算术和逻辑操作,OPR指令通常会取栈顶的一个或两个值进行计算,然后将结果存回栈顶。
所以该条指令牵扯到的函数比较多。
// ⚠️op1和op2的作用范围,op1只在第一次循环使用,op2在第二次及以后使用
expression(){
// 如果match('-'),后续要生成取反指令
op1 <- match('+' or '-')
do
term();
if op1 = '-' gen(OPR,0,1) // 取反指令,要在term之后,因为term会将操作数存入栈中,没有数就无法进行取反
if op2 = '-' gen(OPR,0,2)
if op2 = '+' gen(OPR,0,3)
while(op2<-match('+' or '-');)
}
condition(){
if match("odd")
expression();
gen(OPR,0,6) // 判断是否是奇数
else
expression();
if op<-match(RelOp)
expression();
if op = "==" gen(OPR,0,8)
if op = "<>" gen(OPR,0,9)
...
...
...
}
term(){
do
factor();
if op = '*' gen(OPR,0,4)
if op = '/' gen(OPR,0,5)
while(op<-match('*' or '/');)
}
block(){
const();
var();
procedure();
statement();
gen(OPR,0,0) // 出门,退出当前过程
}
STO
将栈顶的值赋予某变量,这是在赋值运算的时候用到的。现在可以先不纠结为什么第一个参数和第二个参数为什么是这样的,因为这牵扯到第三次实验,想了解的可以结合第三次实验食用。
statement(){
// 双引号内为终结符
if match(ident) assign();
if match("call") call();
if match("begin") begin();
if match("if") if();
if match("while") while();
// 空就不写了
}
assign(){
// 赋值操作
gen(STO, level-table.level, table.address)
}
CAL
过程调用 层次差 程序地址
statement(){
// 双引号内为终结符
if match(ident) assign();
if match("call") call();
if match("begin") begin();
if match("if") if();
if match("while") while();
// 空就不写了
}
call(){
// 查表发现是prodedure类型才行
gen(CAL, level-table.level, table.address)
}
INT
该指令用于在数据栈中分配空间。根据 dx 进行分配,因为 dx 存储了我们当前过程中的变量数+3(DL、SL、AR)。
block(){
const();
var();
procedure();
gen(INT,0,dx);
statement();
gen(OPR,0,0) // 出门,退出当前过程
}
JPC,JMP
条件 / 无条件跳转 的第一个参数都没有意义,都是 0,第二个参数代表程序地址。
无条件跳转:执行该条指令时就直接跳转到第二个参数的位置,然后接着从该位置继续向下执行指令。 条件跳转:相对于无条件跳转需要基于栈顶值的真假进行跳转:
- 栈顶为 0(即 假):跳转到指定位置。
- 栈顶为非零值(即 真):不跳转,继续执行。
JMP
下面先从简单的 JMP 指令开始,思考一下我们什么时候会用到这一条指令:
- 其实第一条指令就是 JMP,因为我们要通过 JMP 来找到我们的主程序(main)在哪。
0 F: JMP L: 0 A: 91
// procedure 的中间代码
...
9 F: INT L: 0 A: 5 // 主程序的第一条指令
...
- 一个 procedure 的中间代码的第一条指令也是 JMP
0 F: JMP L: 0 A: 91
// procedure m 的中间代码
1 F: JMP L: 0 A: 5
// procedure n(嵌套在m里) 的中间代码
...
5 F: INT L: 0 A: 5 // procedure m 的主程序
...
9 F: INT L: 0 A: 5 // 主程序的第一条指令
...
其实上述的两种情况都是同一种情况,因为开始对于程序处理是在 block 里,而 procedure 也是通过 block 处理自己的代码的。因此两种情况都是同一种,所以 JMP 只会在 block 的一开始存在。
我遇到的问题
dx
开始时我的代码为(删除了无关代码,并简化了部分代码):
public void block() {
// 初始化
dx = 3; // 变量的初始地址
genMidCode(InstrucType.JMP, 0, 0);
const(); // 简化处理
var(); // 简化
procedure(); // 简化
midcodeTable.get(cx_0).table.replace("A", cx); // 将跳转位置改到这里
genMidCode(InstrucType.INT, 0, dx); // 分配栈空间
...
}
上述代码有个问题,就是 dx 无法保存,开始时 dx 是正常的,一旦进入 procedure 的处理,因为里面也会调用 block,所以会对 dx 进行初始化,导致退出 procedure 的处理时,外层的 dx 信息会被覆盖,而可以看到指令生成是在 procedure 之后的,恰恰要用到原本的 dx。这可怎么办呢?见下面代码(添加部分用注释标注):
public void block() {
dx = 3;
// int dx_0;
genMidCode(InstrucType.JMP, 0, 0);
const();
// dx_0 = dx;
procedure();
// dx = dx_0;
midcodeTable.get(cx_0).table.replace("A", cx);
genMidCode(InstrucType.INT, 0, dx);
...
}
我再弄一个变量存起来不就行了,但有人可能会问,这个 dx_0,在进入 procedure 的处理时,不是还是会被覆盖吗?内层的 dx 又给了 dx_0,我回到外层 dx=dx_0,获取到的还是内层的 dx 不是原本的 dx。
nonono,这里的 dx_0 是一个局部变量而 dx 是全局变量,局部变量是有作用域的,内层的 dx_0 只能在内层用,到了外层,内层的 dx_0 就没了,所以刚好满足需求。
我用 C++代码模拟了一下运行过程,内部 dx_0 的修改不会影响外部的 dx_0,而在实际的代码中,block1 和 2 是同一个函数,只不过递归调用了而已。
#include <iostream>
int dx;
using namespace std;
void block2()
{
dx = 3;
int dx_0 = dx;
dx_0++;
dx++;
}
void block1()
{
dx = 3;
int dx_0 = dx;
block2(); // 新建了dx_0,并修改dx_0
cout<<dx_0<<endl; // 3
}
int main()
{
block1();
return 0;
}