人工智能-手写识别学习
pytorch 传统网络实现
- 依赖库安装
pip install numpy torch torchvision matplotlib
完整代码
import torch
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision.datasets import MNIST
import matplotlib.pyplot as plt
class Net(torch.nn.Module):
def __init__(self):
super().__init__()
self.fc1 = torch.nn.Linear(28*28, 64)
self.fc2 = torch.nn.Linear(64, 64)
self.fc3 = torch.nn.Linear(64, 64)
self.fc4 = torch.nn.Linear(64, 10)
def forward(self, x):
x = torch.nn.functional.relu(self.fc1(x))
x = torch.nn.functional.relu(self.fc2(x))
x = torch.nn.functional.relu(self.fc3(x))
x = torch.nn.functional.log_softmax(self.fc4(x), dim=1)
return x
def get_data_loader(is_train):
to_tensor = transforms.Compose([transforms.ToTensor()])
data_set = MNIST("", is_train, transform=to_tensor, download=True)
# 一个批次包括15张图片
return DataLoader(data_set, batch_size=15, shuffle=True)
def evaluate(test_data, net):
n_correct = 0
n_total = 0
with torch.no_grad():
for (x, y) in test_data:
outputs = net.forward(x.view(-1, 28*28))
for i, output in enumerate(outputs):
if torch.argmax(output) == y[i]:
n_correct += 1
n_total += 1
return n_correct / n_total
def main():
train_data = get_data_loader(is_train=True)
test_data = get_data_loader(is_train=False)
net = Net() # 初始化神经网络
print("initial accuracy:", evaluate(test_data, net))
optimizer = torch.optim.Adam(net.parameters(), lr=0.001)
# epoch是训练该数据集的轮次,提高数据集的利用率
for epoch in range(2):
for (x, y) in train_data:
net.zero_grad()
output = net.forward(x.view(-1, 28*28))
loss = torch.nn.functional.nll_loss(output, y)
loss.backward()
optimizer.step()
print("epoch", epoch, "accuracy:", evaluate(test_data, net))
for (n, (x, _)) in enumerate(test_data):
if n > 3:
break
predict = torch.argmax(net.forward(x[0].view(-1, 28*28)))
plt.figure(n)
plt.imshow(x[0].view(28, 28))
plt.title("prediction: " + str(int(predict)))
plt.show()
if __name__ == "__main__":
main()
pytorch 卷积神经网络实现
import torch # 用于张量计算和自动求导
import torch.nn as nn # 提供神经网络模块(卷积、全连接层等等)
import torch.optim as optim # 包含优化器模块,用于梯度下降的权重更新
import torchvision # 提供计算机视觉相关的数据集、模型和图像处理
from torchvision import datasets, transforms # datasets数据集、transforms对数据进行预处理
from torch.utils.data import DataLoader # 用于按批次加载数据
from torch.utils.data import Subset # 从数据集中提取子集
# 检查设备是否可用cuda,否则使用CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 超参数
batch_size = 100 # 每次迭代处理的样本数量,一批
learning_rate = 0.001 # 控制每次权重更新的步长
epochs = 2 # 训练完整数据集轮数
# 数据预处理
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,)) # 将数据归一化到 [-1, 1]
])
# 下载 MNIST 数据集
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
test_dataset = datasets.MNIST(root='./data', train=False, transform=transform, download=True)
# 提取数据集子集
# 创建一个包含前 55,000 条数据的子集
subset_indices = list(range(55000)) # 前 55,000 条数据的索引
train_subset = Subset(train_dataset, subset_indices)
# 数据加载器
train_loader = DataLoader(dataset=train_subset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False)
# 定义 CNN 模型
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=32, kernel_size=3, stride=1, padding=1)
self.conv2 = nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, stride=1, padding=1)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
self.fc1 = nn.Linear(64 * 7 * 7, 128)
self.fc2 = nn.Linear(128, 10)
self.relu = nn.ReLU()
def forward(self, x):
x = self.relu(self.conv1(x)) # 第一层卷积 + 激活
x = self.pool(x) # 第一层池化
x = self.relu(self.conv2(x)) # 第二层卷积 + 激活
x = self.pool(x) # 第二层池化
x = x.view(x.size(0), -1) # 展平
x = self.relu(self.fc1(x)) # 全连接层 + 激活
x = self.fc2(x) # 输出层
return x
# 实例化模型
model = CNN().to(device)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# 训练模型
def train(model, train_loader, criterion, optimizer, device):
model.train() # 切换到训练模式
total_batches = len(train_loader) # 计算每个 epoch 的总批次数
for epoch in range(epochs):
total_loss = 0
for batch_idx, (images, labels) in enumerate(train_loader):
images, labels = images.to(device), labels.to(device)
# 前向传播
outputs = model(images)
loss = criterion(outputs, labels)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
# 每 50 批次输出一次训练误差
if (batch_idx + 1) % 50 == 0:
print(f"Epoch [{epoch+1}/{epochs}], Batch [{batch_idx+1}/{total_batches}], Loss: {loss.item():.4f}")
print(f"Epoch [{epoch+1}/{epochs}], Loss: {total_loss / len(train_loader):.4f}")
# 测试模型
def test(model, test_loader, device):
model.eval()
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f"Test Accuracy: {100 * correct / total:.2f}%")
# 运行训练和测试
train(model, train_loader, criterion, optimizer, device)
test(model, test_loader, device)
卷积神经网络学习
-
墙裂推荐:从“卷积”、到“图像卷积操作”、再到“卷积神经网络”,“卷积”意义的 3 次改变
不仅教给我们卷积的知识,还教给我们一种思考方式 🤔,从理论的层面分析了卷积。
-
浙大大佬教你怎么卷 CNN,卷积神经网络 CNN 从入门到实战
系列课程、包括代码实现
- 输入层
- 卷积层:提取特征
- 池化层压缩特征
- 全连接层:加权重
卷积层
卷积神经网络还是一个学习找最优权重参数的过程。
将图像分成很多小区域,对于整个原始输入图像按照一个区域进行加权得到特征图,每个特征图的每个元素是相应位置卷积的结果 32 * 32 * 3,其中 3 表示 RGB 三个颜色通道,多通道分别卷积得到输出再相加。
利用 filter 权重参数进行特征提取,通过特征参数卷积和得到一个值(特征值),filter 前两个值大小表示在原始图像数据中每多大的区域对应一个特征值。不同颜色通道对应的 filter 里的值要不一样,但形状和大小应该一样。 利用内积(对应位置相乘)进行计算,注意加上一个偏置项 Bias b0。
选择不同特征矩阵(规格相同)得到的特征图不同,每一次卷积选择的和是一致的,这样就导致结果有多个,称作为特征图的深度,不用相加而是叠在一起形成深度这一维度。
整个卷积层特征提取过程:将输入图像分隔成很多个像素点以及 RGB 三个颜色通道(例如 32 * 32 * 3,分隔成长为 32 宽为 32,RGB 三个颜色通道),选择 fliter 以及移动距离(步长)进行相应位置卷积加权,将三个计算结果以及偏置加起来可以得到特征图中第一个元素,重复可以得到整个特征图;改变初始权重值可以得到不同的特征图,称为深度。
卷积层涉及参数
- 滑动窗口步长:能移动越多得到的特征图越大,提取的特征越细腻,常见步长为 1
- 卷积核尺寸:选择区域的大小—最后得到结果个数的大小,一般 3×3
- 边缘填充:由于步长选择,有些元素重复加权贡献的,越往里的点贡献多,越往外的点贡献少,是边界点贡献多些,在外面加上一圈 0,可以弥补一些边界特征缺失。zero padding 以 0 为值进行边缘填充
- 卷积参数共享:用同样一组卷积和对图像中每一个区域进行特征提取,减少参数的使用
- 卷积核个数:最后要得到多少个特征图(每个卷积和都是不一样的)
实际计算公式
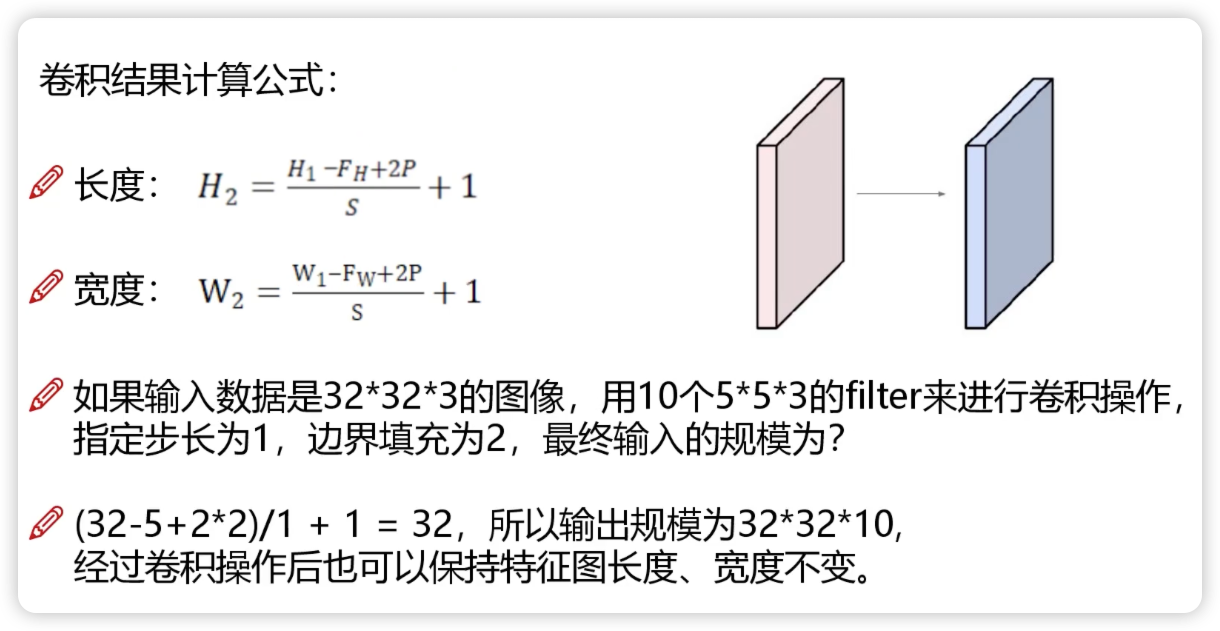
- H1: 输入层长度
- FH: 卷积核长度
- P: 填充多少层 0
- S: 步长
池化层
特征太多了,但并不是都是有用的,因此要进行压缩(下采样),选择重要的留下了,不重要的丢弃,只会对特征图长和宽进行缩减,不会改变特征图的深度,没有涉及到矩阵的计算。
池化层压缩过程:在通过卷积层后对特征图进行筛选,滑动窗口(例如:max pooling 将该区域最大值提取出来)
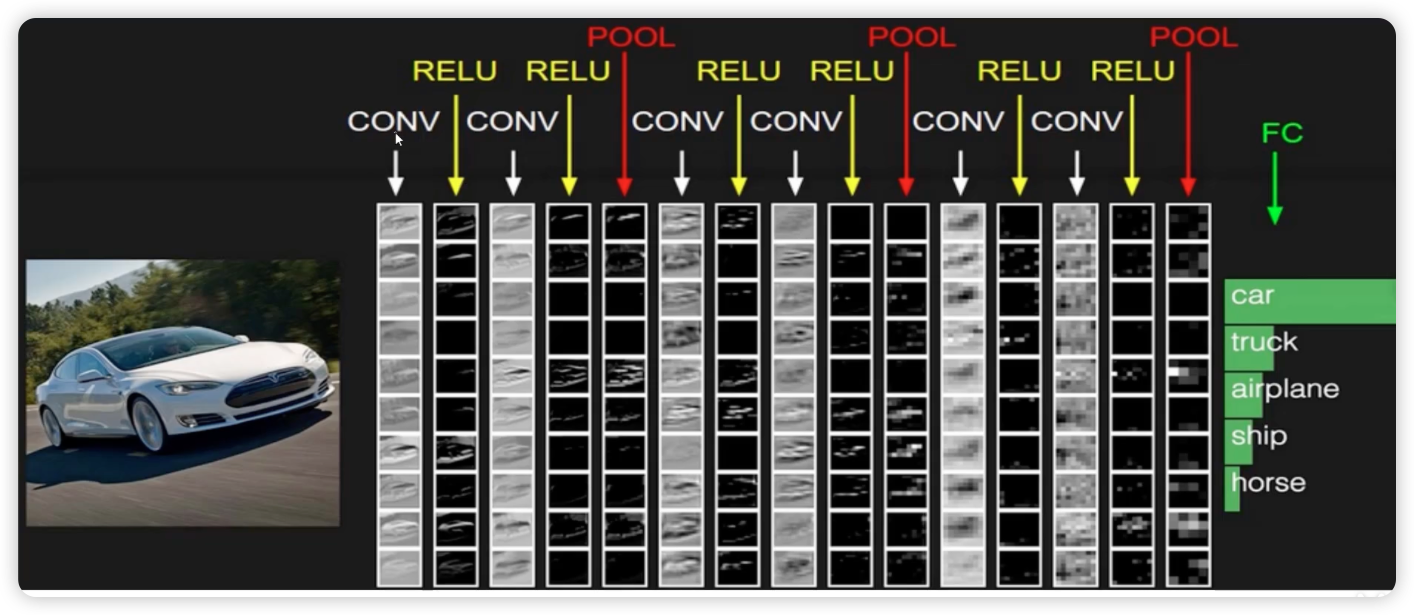
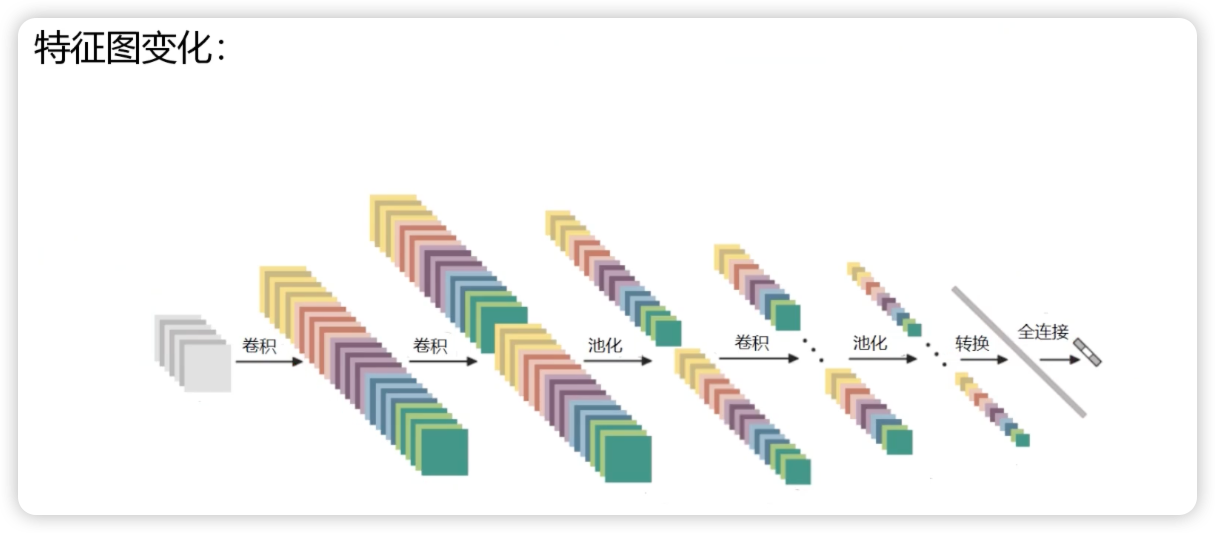
卷积神经网络的框架
每次卷积结束后需要加上一个非线性变换(激活函数),执行几次卷积得到一个比较大的特征图就进行一次池化,最后的结果要转化为分类的概率值(全连接层)
由于全连接层参数不能为 3 维,需要把处理过后的特征图拉成一个特征向量,将该向量转化为各个分类的概率值。
带参数计算才能称作层(卷积层和全连接层,池化层和 RELU 不算层)
历史网络 🕸️
- Alexnet - 12 年
-
VGG 网络 - 14 年
层数比较多,卷积核比较小,卷积核大小都是 3 * 3,经过池化层后会损失一部分信息,在下一次卷积过程中使得特征值翻倍(用特征图的个数–深度,来弥补长宽的损失)
-
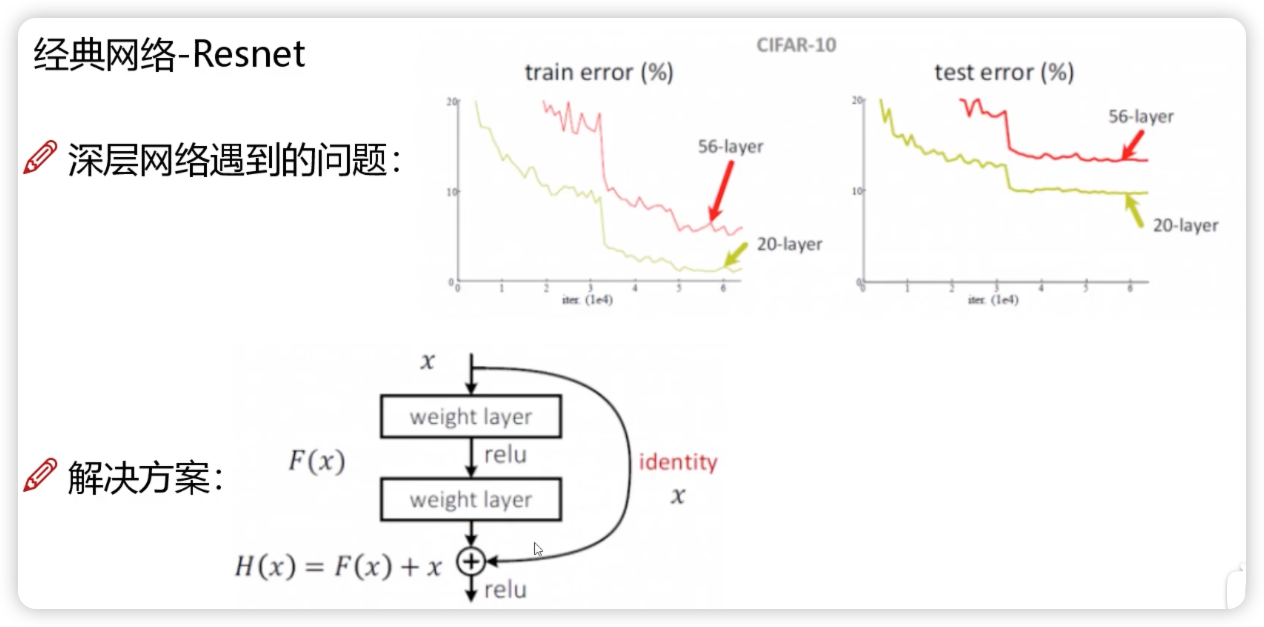
Resnet 残差网络 - 15 年
并不是层数越多越好,在堆叠层数时可能有不好的进行影响,需要设计一个方案进行剔除
可以理解为经过卷积层后学的不好把原来学的好的覆盖了,现在重新构建堆叠原始学的好的那部分,即使之前不好的部分有影响,但只要学习使得该部分权值为 0 即可(好的我用,不好的我权重为 0,相当于白搞,也就是对我有用的我加上,没用的我也加上但是不影响,最后效果至少一定不会比原来差)
感受野
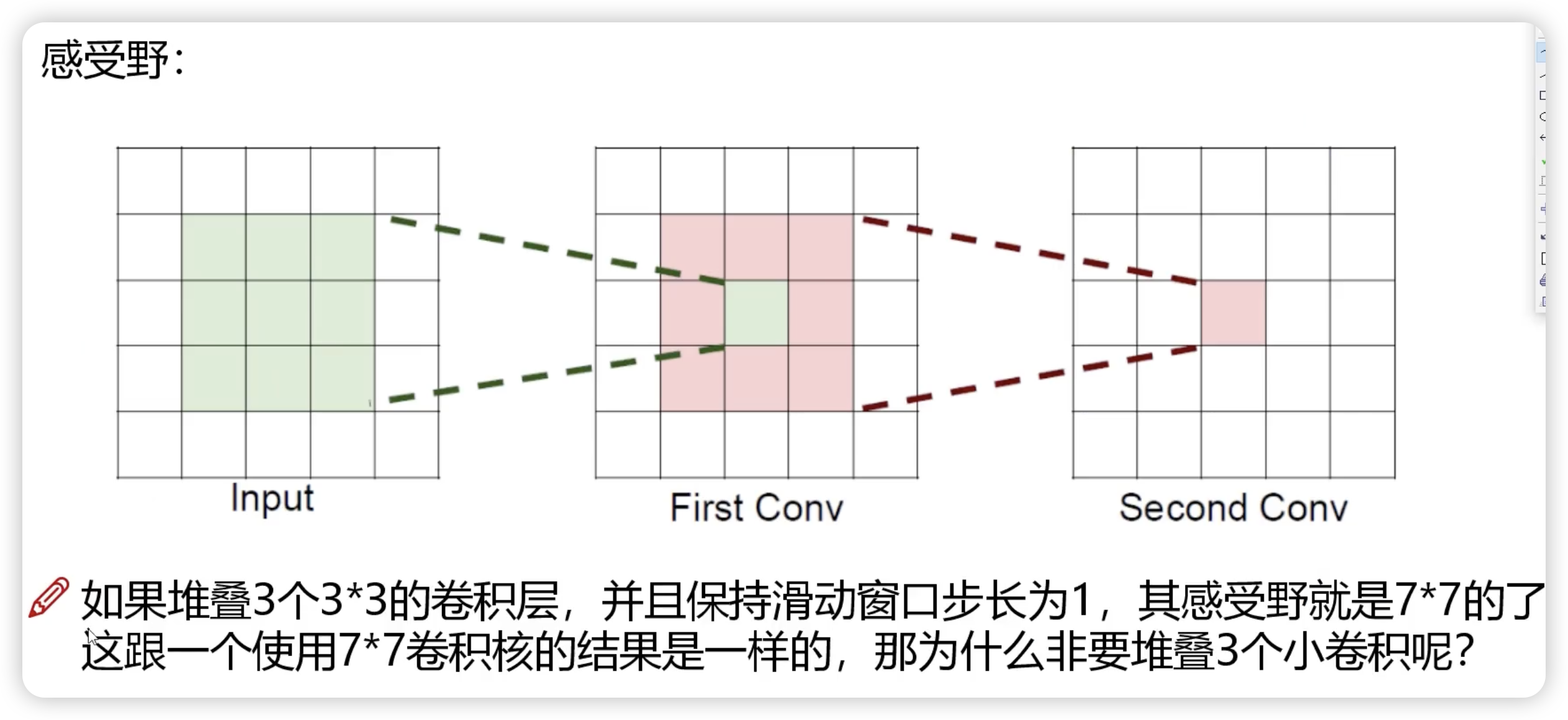
当前这个值是由前面多少个值参与计算得到的,一般希望感受野越大越好。3 个 3 * 3 卷积层需要的参数比一个大的要参数小,实际效率更快一些。计算速度与参数个数挂钩,卷积越多越细腻,加入的非线性变换野随着增多
